

Массив упоминаний в социальных медиа имеет «слоёную» структуру: здесь и оценочные отзывы пользователей, и информационные поводы, и рекламные публикации. Для того чтобы извлечь из больших данных ценные аналитические выводы, массив необходимо «приготовить», т.е. привести к «чистой», релевантной форме. Степень релевантности того или иного типа сообщений определяется целью мониторинга: слой оценочных отзывов пользователей подходит для выявления конкурентных преимуществ и проблемных зон продукта, а репосты конкурсов необходимы для оценки маркетинговой эффективности.
Оригинальный алгоритм подготовки массива упоминаний соцмедиа к аналитике от Brand Analytics опирается на ключевой вопрос о цели мониторинга. Цель служит своеобразным фильтром, который в каждом конкретном случае позволяет решить, какие слои в массиве являются ценными, релевантными, а какие – наоборот, нерелевантным «мусором». На предварительном этапе подготовки данных необходимо взвесить, каких слоев больше – релевантных или нерелевантных. Если в составе данных преобладает релевантное ядро, проведите процедуру чистки от спама, рекламы и косвенных упоминаний (Часть 1).
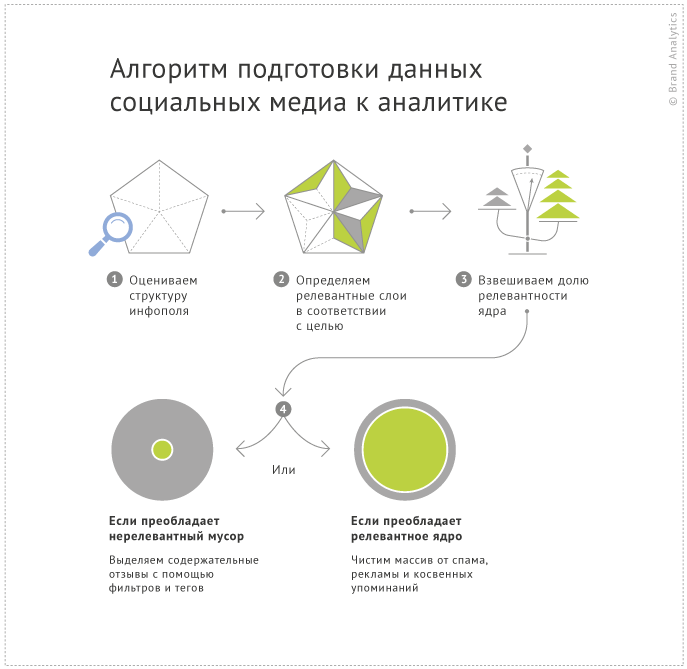
В данной части мы подробно расскажем про второй случай – когда релевантные для нас слои составляют меньшую часть данных. Если массив сообщений слишком «грязный», и для его анализа нам нужна меньшая доля, то стоит в корне изменить сам процесс. Вместо того чтобы чистить лишнее, мы пойдем к цели напрямую и возьмем только нужное. Мы не будем очищать иголку от стога сена, а просто поднесем магнит, который вытянет нашу иголку. Аналитический функционал системы мониторинга имеет множество помощников для выделения релевантного ядра (своеобразные магниты для иголок).
Практические механизмы выделения релевантного ядра
В системе мониторинга Brand Analytics есть тонко настраиваемая совокупность тегов и фильтров, которая позволяет, не очищая массив от лишнего, выделить только важное. Порядок применения данного класса инструментов зависит от различных факторов: цели исследования, типа и структуры соцмедийных данных в конкретной теме мониторинга, наличия характерных словосочетаний-клише, позволяющих выделить релевантные слои. Для лучшего усвоения материала разложим 3 важнейших практических механизма выявления релевантного ядра по следующей схеме: условия применимости, алгоритм реализации механизма и примеры из практики аналитического центра.
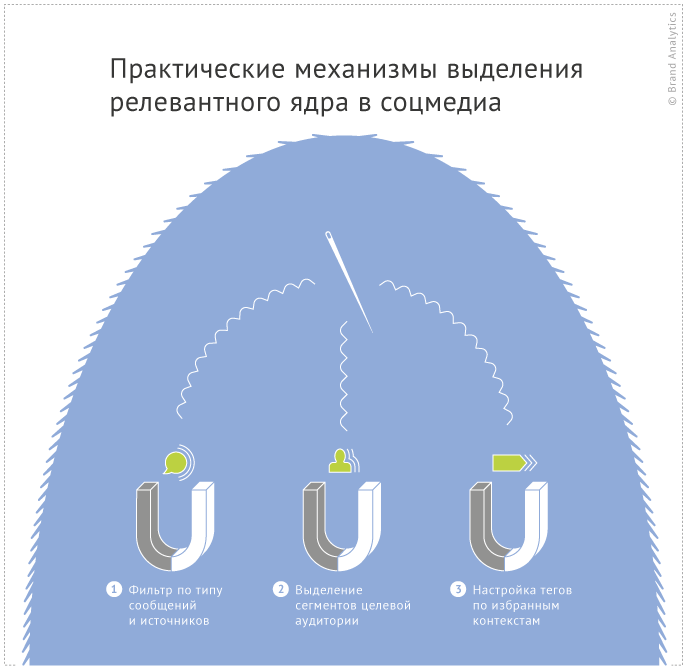
1. Фильтр по типу сообщения/источника
Когда полезен метод. Данный метод экономит трудозатраты на подготовку данных к аналитике в случае, когда Вас интересует определенный тип сообщений: оценочные отзывы пользователей или новостные публикации. Типизированные слои сообщений в системе легко выделяются с помощью фильтров по источнику и по типу сообщения.
Как это сделать. Если Вас интересуют только оценочные отзывы пользователей, мы можем применить встроенный в систему фильтр по источникам – так, максимальная концентрация оценочных отзывов пользователей сосредоточена специализированных форумах и сайтах с отзывами. Для быстрого поиска оценочных отзывов пользователей применяем фильтр по типу источников – в меню фильтров справа выбираем «Форумы», «Отзывы» и жмем кнопку «Отфильтровать» внизу.
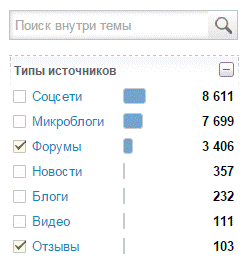
Данный тип фильтрации позволяет быстро выделить значительную часть релевантного ядра. Однако, это еще не все: большой массив оценочных отзывов пользователей содержится в социальных сетях и блогах, извлечь их оттуда чуть сложнее. Дело в том, что соцсети содержат разнородные слои сообщений – здесь смешиваются реклама, репосты новостей, мемов и промо-материалов, и оценочные отзывы пользователей. Их разделению может поспособствовать другой тип фильтрации, расположенный в ленте под текстом сообщения. Сообщения маркируются по типу: пост, репост или комментарий.

Для того чтобы выделить нужные слои сообщений, достаточно зайти в его тип и щёлкнуть «Отфильтровать по типу сообщения». Так, оценочные отзывы в социальных сетях, в основном, содержатся в комментариях к головному посту – обзору. Вы можете быстро выделить эти сообщения, применив фильтр по типу сообщений «Комментарий». Если Вам интересно распространение новостных публикаций и промо-активностей, фильтруйте по типу сообщения «репост».
Примеры. Чтобы отследить отзывы аудитории социальных медиа о новом Apple iPhone 7, мы применили фильтр по типу источников «Форумы» и «Отзывы», которые объединяют специализированные технические ресурсы 4PDA, Hi-Tech.Mail.ru, Mobile-Review и т.д. В отфильтрованном потоке в концентрированном виде представлены оценочные отзывы аудитории, содержащие качественную оценку смартфона. Следующим шагом выделили содержательные высказывания пользователей в фильтрах «Соцсети» и «Микроблоги» — для этого фильтруем ленту по типу сообщения «комментарий».
2. Фильтры по сегментам целевой аудитории
Когда полезен метод. Данный вид фильтрации способен значительно ускорить обработку данных в случае, когда сформирован портрет целевой аудитории. Если Вас интересует активность конкретных сегментов целевой аудитории в соцмедиа, Вы можете легко повысить релевантность базы данных, применив многопараметрическую фильтрацию. Нам нужен конкретный сегмент целевой аудитории продукта (например, только девочки-подростки из Санкт-Петербурга), то можно просто применить смешанную фильтрацию по возрасту (до 18 лет), полу (женский) и городу (Санкт-Петербург). Так, в один клик мы получим релевантный для нас срез данных.
Как это сделать. Для применения этого метода необходимо обозначить характеристики целевой аудитории бренда по трем основополагающим категориям: география, возраст и пол. Ориентирован ли Ваш бренд преимущественно на женщин или на мужчин? В какую возрастную категорию попадает Ваш целевой потребитель? Ограничена ли география продаж Вашего бренда на уровне страны, города? Если целевая аудитория Вашего бренда смещена в какую-либо категорию по одному (или нескольким) пункту, Вы можете легко отфильтровать контент от интересуемого сегмента. Для этого в меню фильтров справа можно выбрать любой набор фильтров по географии, полу и возрасту.
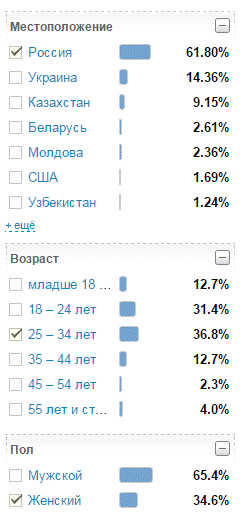
Примеры. Рассмотрим мониторинг на этапе вывода нового продукта на рынок. Компания решила запустить в России разновидность флагманского смартфона, ориентированную на состоятельных женщин. Представление новой «женской» версии телефона планируется в кооперации с производителем дорогих сумок в едином кожаном дизайне. Для анализа предпочтений женщин относительно цветов и текстуры корпуса, а также предпочитаемой функциональности, в системе мониторинга Brand Analytics представитель подразделения разработки новых продуктов фильтрует массив упоминания флагманского смартфона по полу «Женский», возрасту «25-34 лет», «35-44 лет», «45-54 лет» и «55 лет и старше» и географии «Россия». В пару кликов мы получаем отборное «зерно» — мнения целевого сегмента, на основе которых можно разработать оптимальный дизайн, функциональность и продвижение нового продукта.
3. Настройка тегов по избранным контекстам
Когда полезен метод. Данный метод позволяет быстро выделить релевантное ядро в тех ситуациях, когда нас интересует избранная категория внутри общей темы мониторинга. Основное условие применимости метода – это возможность выделить сообщения нужной категории с помощью ключевых слов. В качестве такой категории чаще всего выступают:
- Конкретное свойство продукта (функциональность, удобство использования, дизайн или цена),
- Конкретный контекст упоминаний продукта (сообщения о технических проблемах, упоминания топов компании и прочих знаменитостей в контексте бренда),
- Конкретное подразделение сетевого бизнеса (например, Шоколадница на Остоженке или фитнес-клуб World Class Романов пер.),
- Совместные упоминания с конкурентами (сравнительные упоминания Coca-Cola и Pepsi в тексте одного пользовательского отзыва).
Как это сделать. Если мы определились с конкретным контекстом упоминания бренда, который составляет небольшую долю в общем массиве, нам необязательно разбирать стог сена, чтобы найти иголку в нем – достаточно воспользоваться магнитом: в системе Brand Analytics магнитом для выделения нужно контекста выступают теги. Формируем ядро релевантных слов/словосочетаний, которые употребляются в интересующих нас сообщениях, и создаем новый тег (для этого необходимо зайти в отчет «Теги» на панели слева). В поле поискового запроса через запятую перечисляем уточняющие словесные паттерны, определяющий избранный контекст. Язык поисковых запросов и принцип подбора слов «минус» при создании тега аналогичны этапу создания темы.
Обращаем Ваше внимание, что на этапе создания тега можно не вводить в поле поиска название самого бренда, достаточно задать только уточняющий контекст – поиск по нему будет производиться внутри собранной темы мониторинга.
Примеры. Рассмотрим примеры создания тегов в различных ситуациях приоритетного релевантного ядра. В таблице ниже приведены примеры слов/словосочетаний, которые помогают быстро выделить релевантные слои упоминаний в качестве тега внутри темы.
| № |
Избранный тег |
Слова для настройки тегов |
|
1 |
Определенное свойство продукта: автономность батареи в iPhone 6уточненный «сленговый» запрос для выявления отзывов аудитории |
энергопотребление, автономность, батарея, заряд, аккумулятор, аккум “дохлая батарейка”~2, “держит заряд”~3, “жрёт аккум”~2, “ быстро сдох”~5 |
|
2 |
Подразделения сетевого бизнеса: дилерский центр Порше в Москве на Кутузовском проспекте |
Кутузовский, Кутузон, “Времена Года”~0, Дорогомилово, Дорогомиловский, Кутуза |
|
3 |
Сравнения с конкурентами: Совместные упоминания Coca-Cola c основным конкурентом — Pepsi |
Pepsi, Пепси, PepsiCola, Пепсикола, Пэпси, Пэпсикола, PepsiLight, Пепсилайт, Пэпсилайт |
|
4 |
Избранный контекст упоминаний: Реагирование на жалобы аудитории бренда программного обеспечения |
проблема, дефект, брак, бракованный, баги, глюки, глючить, заглючить, лаги, лагать, тормоза, тормозить, неисправность |
Тема мониторинга содержит богатый материал живых разговорных клише, обобщение которых в виде тегов позволят выделить те или иные интересующие группы сообщений.
Вместо заключения
Итак, мы пошагово проанализировали процесс подготовки данных в социальных медиа к аналитике. В сложном случае, когда нерелевантные слои сообщений заполняют большую часть массива, имеют разнородную структуру и, соответственно, требуют значительных затрат по чистке, на помощь аналитику приходит функционал настраиваемых фильтров и тегов. Если можно охарактеризовать релевантное ядро массива определенным типом сообщения/источника, портретом целевой аудитории или наличием характерным слов в текстах сообщений, то стоит на 180˚ изменить сам подход к подготовке массива: вместо чистки массива выделяем релевантное ядро с помощью «магнитов», описанных в статье.
Стоит отметить, что сложный, качественный характер текстовых данных в социальных медиа далеко не всегда позволяет обойтись одним практическим инструментом для получения «чистого», релевантного потока. Для получения наилучшего результата в большинстве тем мониторинга требуется комбинация нескольких методов выявления релевантного ядра – многопараметрическая фильтрация в тандеме с настройкой тегов. Главное правило, которым стоит руководствоваться на этапе «приготовления» данных социальных медиа – это целесообразность: каждый случай требует индивидуального, внимательного подхода в выборе оптимальных инструментов «очистки» массива.
