

Совокупность упоминаний бренда в соцмедиа зачастую представляет собой разнородный массив данных, включающий репосты новостей, оценочные отзывы пользователей, рекламу, самоцитирование. Прежде чем приступать к интерпретации данных, массив упоминаний необходимо сделать “чистым”, релевантным. Тщательная подготовка данных социальных медиа – залог качественной аналитики. В статье раскрываются эффективные алгоритмы чистки массива от спама, рекламы и нерелевантных упоминаний.
Что у нас в фокусе?
Необходимым условием качественной проработки массива является наличие приоритетной цели. Что Вы хотите получить от мониторинга социальных медиа? Оперативно отследить негативные инфоповоды? Проанализировать деятельность конкурентов? Выявить точки притяжения целевой аудитории? Оценить эффективность рекламной акции? В зависимости от выбранной цели, процесс чистки массива имеет различное число уровней. Чтобы лучше понять данный процесс, обратимся к природе больших данных соцмедиа – представим массив в виде белокочанной капусты. Массив упоминаний, как и капуста, — не монолитное соединение, у массива есть слои. Метод очистки как капусты, так и массива, определяется целью: хотим ли мы на выходе получить салат, свежевыжатый сок или обертку для голубцов. Расстановка приоритетов ускорит извлечение качественного, релевантного потока упоминаний в социальных медиа.
Структура массива упоминаний бренда в соцмедиа
Чтобы осознать слоёную структуру информационного поля соцмедиа, рассмотрим пример массива сообщений о бренде «Бойкая капуста».
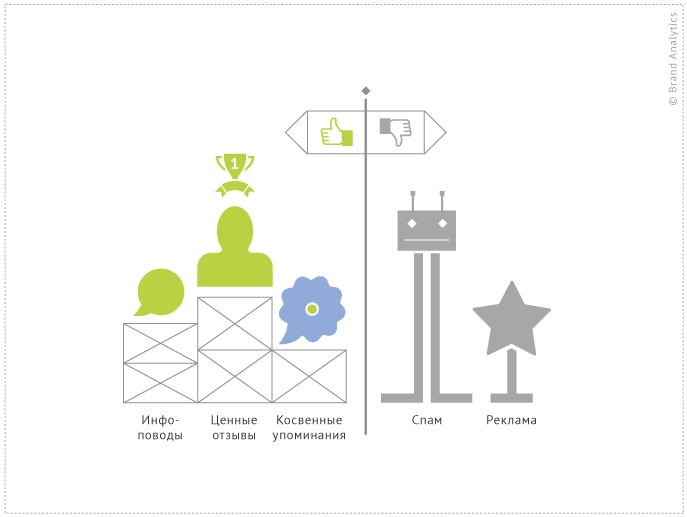
1) Самый сок массива составляют содержательные отзывы аудитории, выражающие оценку бренда. Анализ палитры мнений целевой аудитории позволяет сформулировать сильные и слабые стороны продукта, а также выявить скрытые инсайты, позволяющие усилить лояльность клиентов.
“Девочки, 5-й день, как перешла на правильно питание, по вечерам такой жор нападает, спасаюсь Бойкой капустой. Только неудобно на прогулку брать – рассыпается. Да и руки грязные, нездорово ”.
2) Значительная категория сообщений о «Бойкой капусте» — это новости бренда, а также их репосты в социальных сетях.
“20 июля холдинг Бойкая Капуста закончил процесс поглощения своего основного конкурента – ОАО Резвая Морковка”.
3) Существенную долю массива составляют косвенные упоминания «Бойкой капусты», в которых бренд упоминается вскользь. Ценность таких сообщений колеблется в зависимости от целей исследования.
“Место встречи – улица Овощной ряд, д. 5. Сворачивайте в арку сразу за главным офисом «Бойкой капусты» и двигайтесь 5 минут в северо-западном направлении”.
4) Низкую аналитическую ценность заключают рекламные публикации.
“Бойкая капуста объявляет акцию. При заказе 3-х брикетов четвертый – в подарок!”
5) За пределами релевантного ядра находятся и сообщения спам-ботов.
“Скачать, смотреть онлайн, Бойкая капуста, Виагра, без регистрации”.
Как мы видим, информационное поле бренда неоднородно – в зависимости от темы мониторинга оно может содержать различные группы сообщений: новостные материалы, реклама, оценочные отзывы пользователей и т.д. В зависимости от целей мониторинга мы адаптируем направление и степень очистки массива: так, для SWOT-анализа продукта принципиально важны только содержательные отзывы пользователей, а для оценки активности купли-продажи могут пригодиться и рекламные публикации. Специалисты аналитического центра Brand Analytics впервые представляют схему подготовки массива к аналитике. Будьте осторожны! Легкость восприятия, которую открывает наш алгоритм, может открыть в Вас безудержное желание анализировать большие данные в социальных медиа.
Определите и взвесьте то, что является релевантным для Вас
Итак, приступая к работе с массивом данных соцмедиа, мы определяем его структуру для конкретной темы. Ключевой пункт, который нужно сделать до начала собственно процедуры “чистки” – это определить релевантные для цели исследования слои данных. Какие типы сообщений считает значимыми сама компания – содержательные отзывы целевой аудитории продукта, мнения экспертов рынка, скорость и масштаб распространения главных новостей, сравнительные обзоры по конкурентам?
Вспомним капусту: и зеленые, и белые листья, и кочерыжка представляют определенную ценность. То, что мы считаем релевантным, определяется нашей целью – хотим ли мы нашинковать салат, приготовить голубцы или выжать сок. В исследованиях социальных медиа действуют те же базовые принципы целесообразности, что и в природе. Мы берем ту часть массива упоминаний, которая содержит релевантную информацию для конкретной цели.
Второй стержневой пункт – это осознать, какую долю в общем массиве занимает релевантная часть. Положим на одну часть весов релевантную часть потока, а на другую – “мусор”. Что перевесит? Ответ на это вопрос сэкономит Вам бесценное время в процессе чистки массива.
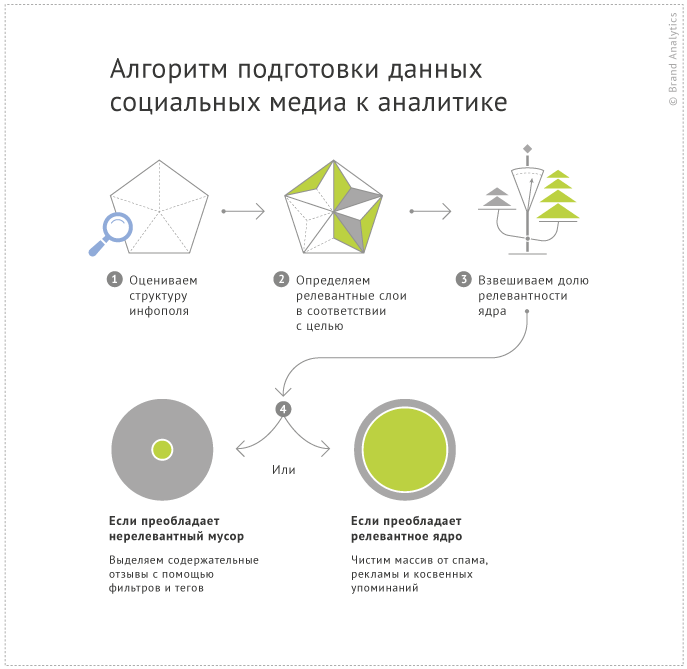
1) Перевешивает релевантное ядро. Если интересующие нас сообщения составляют большую часть массива, и не выделяются автоматическими фильтрами, то “счистим шелуху” – малосодержательный слой массива. В следующих разделах статьи дается подробное практическое руководство по очистке массива от спама, рекламных и косвенных упоминаний.
2) Преобладает нерелевантный “мусор”. Если массив сообщений слишком “грязный”, для анализа нам нужна его меньшая часть, то стоит в корне изменить сам процесс. Вместо того чтобы чистить лишнее, мы пойдем к цели напрямую и выделим значимое, релевантное ядро при помощи уточнения запроса и встроенных фильтров.
Практические механизмы чистки массива соцмедиа
Для эффективной проработки темы воспользуемся готовыми алгоритмами очистки массива, разработанными специалистами аналитического центра Brand Analytics. Данные методы зарекомендовали свою эффективность в случаях, когда в массиве данных преобладает релевантная часть и легче счистить “мусор”, чем выделить все нужные слои. «Грубая» очистка данных отсеивает слои, имеющие нулевую аналитическую ценность, — сообщения спам-ботов, омонимичные сущности, не относящиеся к объекту, рекламные публикации и косвенные упоминания.
1. Исключение спама.
В первую очередь, под нож попадает откровенный спам, сгенерированный автоматическими бот-аккаунтами. Сообщения спам-ботов не нужны для 95% исследований: продолжая аналогию потока с белокочанной капустой, можно сравнить данный слой массива с крайними наружными листьями капусты. Жесткие, изодранные, с перемежающимися сорняками, в земле, эти листья уже ни на что не годны, и подлежат, как и спам, удалению. В системе мониторинга имеется встроенная фильтрация спама: чтобы не пропустить армию ботов в наш массив, рекомендуется включить автоматический спам-фильтр в окне создания темы.

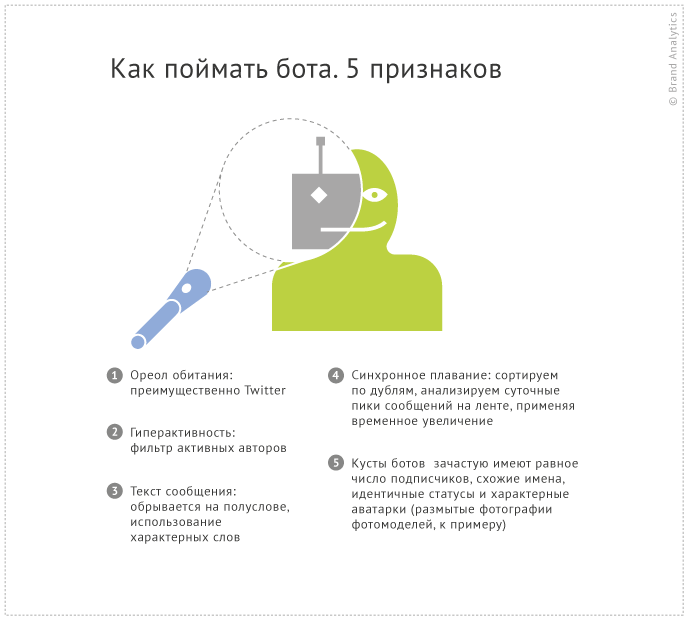
Решето автоматического фильтра позволяет отсеять большую часть спама, тем не менее, некоторым свежеиспеченным, усовершенствованным ботам удается проникнуть в тему. Отловить данных ботов помогут эмпирически выявленные признаки бот-активности и комплекс системных фильтров и сортировок. Они позволяют быстро проанализировать подозрительные споты концентрации типовых спам-аккаунтов.
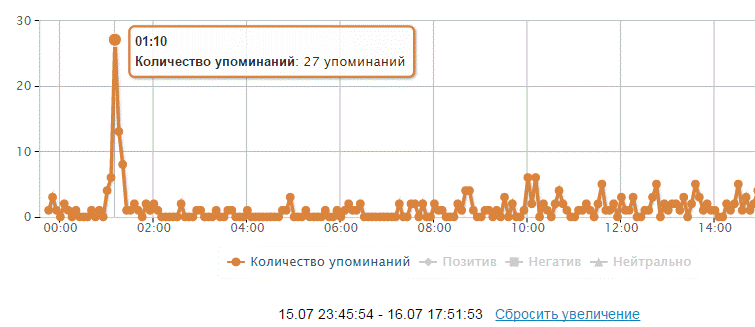
Характерной особенностью ботов является их стайный образ жизни. Для того чтобы обнаружить куст ботов (их типовые аккаунты имеют близкие значения аудитории, публикуют одинаковые сообщения примерно в один момент времени), в системе Brand Analytics рекомендуется начинать с 3-х видов упорядочивания потока: выделение суточных пиков упоминаний на ленте, сортировка по дублям и по аудитории. Стартуем с внимательного взгляда на динамику упоминаний в течение дня. Любые резкие скачки упоминаний – это повод насторожиться: пик может означать как всплеск интереса аудитории после «жирного» инфоповода, так и банальную бот-атаку. Посмотрим на пример суточной динамики упоминаний ниже: резкий рост упоминаний в 1.10 ночи с 3 до 27 сообщений дает веские основания подозревать активность спам-роботов.
Чтобы проверить гипотезу, применяем временное увеличение – выбираем на ленте сообщений час пиковой активности. В случае небольшого числа сообщений можно быстро прочитать их для определения вероятности бот-атаки (о том, как это сделать, читайте далее). Если число сообщений очень велико, для выявления ботов удобно применить сортировку по дублям.
На панели над лентой сообщений кликаем “Сортировать по: Дублям”, таким способом мы группируем публикации с идентичным текстом в одну ячейку.
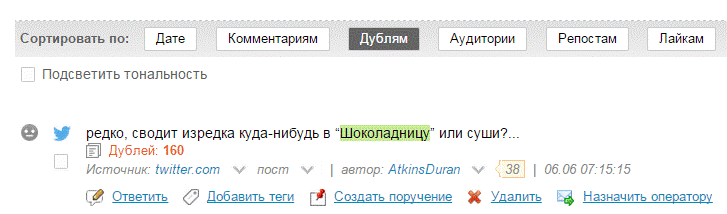
Определить степень «человечности» авторов дубликатов легко, в качестве подсказки можно использовать следующую схему косвенных признаков:
1) Насколько осмыслен текст сообщения? Автоматические спам-аккаунты зачастую вырывают фразу из контекста, обрывают текст на полуслове так, что смысл текста вообще понять невозможно. Например, “в Москве прошел первы” или “ции скачай бесплатно #mobiletech без регистра”.
2) Можно ли подвести авторов дубликатов под типизированный прототип? Имеют ли авторы схожие имена, близкие значения аудитории, типичные аватарки/статусы? Для анализа этих параметров удобно раскрыть список дублей и их авторов, кликнув на ссылку “Дублей: N” под текстом поста.
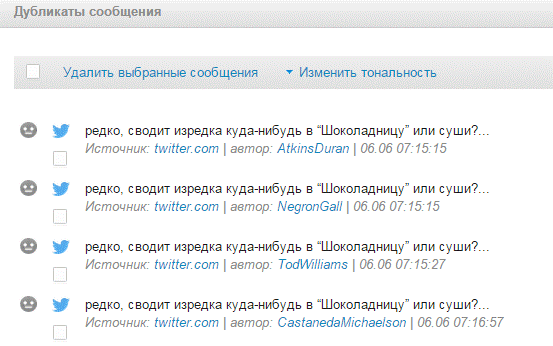
В нашем примере мы наблюдаем несколько признаков куста ботов – дубли имеет абсолютно идентичный вид (без авторский приписок), отправлены в узком временном интервале (1-2 минуты). Имена авторов имеют типовый формат TodWilliams, NegronGall, AtkinsDuran (фамилия пишется слитно с именем, на латинице, не указана география). Переход на профили авторов в Твиттер подтверждают, что это боты: все используют размытые аватарки из Интернета, имеют порядка 50 читателей, а также успели опубликовать 100-135 тыс. твиттов за время своей “жизни”.
Рекомендуется удалять не только подобные сообщения, но и авторов спама из темы, чтобы исключить попадание лишнего шума в поток в дальнейшем.
При наличии характерных выражений, используемых бот-авторами, следует также внести закавыченные словосочетания в поле “Минус-слова” в окне редактирования настроек темы. Например, в автоматических спам-текстах зачастую можно встретить такие выражения, как “без регистрации и смс”, ”скачать бесплатно”, ”в и а г р а”.
2. Нерелевантные сущности.
Другая категория слов, которые следует минусовать, — это омонимичные и пересекающиеся в названиях сущности. Так, словом капуста обозначают различные ее виды: белокочанную (чаще всего), цветную, брюссельскую, китайскую и т.д. Если мы хотим настроить мониторинг только упоминаний обычной капусты (белокочанной), то нам нужно исключить из сбора другие сорта. Вносим в минус-слова темы “пекинская капуста”~0, “цветная капуста”~0 (добавка ~0 позволяет учитывать все морфологические формы указанных выражений). Данный тип фильтрации является must-have для заковыристых названий брендов. Яркие примеры — сок «Я», газета «Моё!», одежда «Твоё» (совпадают с местоимениями).
3. Фильтр активных авторов против рекламы.
Рекламные группы и агенты влияния обычно отличаются повышенной активностью, заполоняя социальные сети хвалебными речами в адрес продукта и объявлениями о беспрецедентных скидках. Для выявления таких авторов/сообществ удобно воспользоваться фильтром по авторам, просмотрев деятельность ТОП-10 наиболее активных авторов темы. Обычно значительная доля этого списка приходится на самоцитирование, рекламные группы и вербованных агентов, сообщения которых в большинстве случаев можно смело убрать в корзину.
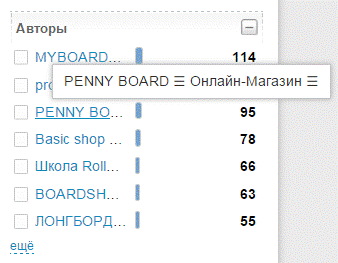
Для оперативного выявления рекламных сообществ сканируем сообщения самых активных авторов темы в окне фильтрации “Авторы” справа. Можно удалить не только рекламные сообщения, но и лишних авторов из темы: в этом случае система не будет пропускать такой массив в дальнейшем. Для этого нужно отфильтровать сообщения по нужному автору, выбрав его в окне фильтрации. Выберем все сообщения авторов за период внизу ленты.
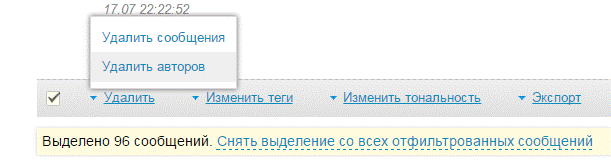
В окне доступных опций удаления выбираем “Удалить авторов” – с этого момента сообщения “Черного списка” перестанут засорять тему.
4. Ядро лишних слов против рекламы и косвенных упоминаний.
Еще один мощный метод позволяет не только очистить массив от лишних рекламных сообщений, но и удалить слой косвенных упоминаний, где бренд упоминается вскользь, между делом (данный тип сообщений также не имеет практически никакой аналитической ценности). Метод состоит в выявлении характерных паттернов, словесных конструкций, которые употребляются в нерелевантных сообщениях. Например, при анализе банка зачастую в тему попадают сообщения о регулярных колебаниях курсов валют в этом банке или посты с призывом сбора денег для помощи больным детям, в которых указываются реквизиты счета в банке. При проведении мониторинга бренда строительных материалов в поток попадают рекламные сообщения бригад, которые оказывают услуги с привлечением материалов данного бренда. В теме оператора сотовой связи название бренда (например, Билайн) часто встречается “между делом”, при указании контактных данных человека в социальных сетях, например: “Мастер по маникюру, выезд на дом. Звоните 8965356XXXX (Билайн)”. Данный слой массива, содержащий упоминания бренда, хотя и может быть полезен при подсчете статистики узнаваемости в социальных сетях, зачастую оказывается нерелевантным при проведении качественных исследований big data. Чтобы эффективно отсечь подобные слои упоминаний, специалисты аналитического центра Brand Analytics рекомендуют использовать ядра “лишних слов”. Они представляют собой списки характерных словосочетаний для рекламных/косвенных упоминаний, которые адаптируются под конкретную отрасль и цель исследования. Ниже приводим примеры паттернов, которые идентифицируют “шелуху” в разных отраслях мониторинга.
| Отрасль | Примеры ядра “лишних слов” |
| Банки | Косвенные упоминания банка в сообщениях об изменении курса валют от пунктов обмена в социальных сетях«Занимаюсь обменом», «Курс eur», «Курс usd», «Курсы валют», «Курс руб»~2Косвенные упоминания банка при указании реквизитов (обычно – сбор средств на лечение, восстановление храма)«qiwi кошелек»~0, «, «оплата на карту», «потерянное детство», «почтой по России», «расчет наличными», «собрано», «способ помочь», «№ КАРТЫ», БИК, ОКАТО |
| Телеком | Косвенные упоминания оператора связи при указании контактного номера телефона в социальных сетях«запись по тел»~0, «мои контакты», «для заказа звоните»~0, «запись по телефону»~0, «звони прямо сейчас», «звоните по номеру» магазин, «мой контактный телефон»~0, заказать «по телефону»~0 |
| Сетевые кафе | Косвенные упоминания сетевого кафе как ориентира для места встречиЗайти в арку рядом с кафе “Шоколадница”, под навесом у “Ваби-Саби”, напротив “Теремка”, возле ПапаДжонни |
| Строительные материалы | Рекламные сообщения бригад, работающих с брендом«бесплатная доставка»~0, «в наличии», «звоните», «руб шт»~2, «установка монтаж»~5, «продаётся», скидки, «продаю», «команда экспертов», объявления, «малярные работы»~2, «монтажные работы»~2, «супер цена»~2, «под ключ», “акционные цены”~0, “оптовые цены”~0, оптовики, оптом, дешево, распродажа, «гарантия качества»~2, |
| Авиакомпании | Рекламные сообщения горячих туров, осуществляющих вылет на самолетах исследуемой авиакомпании«горячие туры»~0, “Купить Авиабилеты”, тур “ночей”, тур “дней”, “Заказать Авиабилет”, “вылеты ежедневно” |
Используя поиск по теме, сканируем взглядом сообщения по ядру “лишних слов”, чтобы убедиться, что вместе с шелухой мы не теряем ценных отзывов пользователей. Ненужный слой легко снимается массовым удалением.
Заключение
Массивы big data в социальных медиа в начале работы могут пугать своими объемами и многослойностью. Масштаб и разнородность текстовых данных действительно оборачиваются большими трудозатратами, если подходить к их обработке “в лоб”, теряя лес за отдельными деревьями.
Мы рассмотрели эффективные алгоритмы чистки массива данных в случае преобладания релевантного потока. В следующей части мы расскажем, как легко выделить значимое, релевантное ядро, когда в массиве преобладает “мусор”.
